Klasifikasi Penyakit Pada Tanaman Mangga Dengan EfficientNetB3 Berdasarkan Citra Daun
Klasifikasi Penyakit Pada Tanaman Mangga Dengan EfficientNetB3 Berdasarkan Citra Daun
Pendahuluan dan Studi Terkait
Mangga (Mangifera indica) merupakan salah satu buah yang sangat penting di Indonesia, baik dari segi ekonomi maupun konsumsi. Sayangnya, tanaman mangga sering terpapar berbagai penyakit daun yang dapat mengurangi hasil panen hingga 30% jika tidak segera terdeteksi (FAO, 2023). Oleh karena itu, penting untuk memiliki metode deteksi penyakit yang cepat dan akurat agar dapat mengurangi kerugian yang mungkin terjadi.
Seiring dengan berkembangnya teknologi kecerdasan buatan (AI), terutama di bidang pengolahan citra digital, kita kini bisa memanfaatkan teknologi ini untuk mengklasifikasikan penyakit tanaman melalui analisis citra daun. Model Convolutional Neural Network (CNN) seperti EfficientNetB3 memiliki kemampuan tinggi dalam hal efisiensi komputasi, menjadikannya pilihan yang baik untuk diterapkan dalam klasifikasi penyakit tanaman.
Berikut adalah gambaran tentang bagaimana proses klasifikasi penyakit tanaman dapat dilakukan menggunakan citra daun::

Gambar 1. Ilustrasi klasifikasi penyakit daun mangga berbasis citra menggunakan model CNN.
Sejumlah penelitian sebelumnya telah mengeksplorasi penggunaan arsitektur CNN lain seperti ResNet, VGG, dan MobileNet untuk klasifikasi penyakit tanaman, dengan tingkat akurasi yang berkisar antara 80-90% (Smith et al., 2022; Lee et al., 2021). Namun, penelitian dan proyek mengenai penggunaan EfficientNetB3 untuk klasifikasi penyakit pada tanaman mangga masih terbatas. Oleh karena itu, proyek ini bertujuan untuk mengisi kekosongan itu dengan menguji efektivitas model EfficientNetB3 dalam mendeteksi penyakit pada daun mangga.
Deskripsi Metode
Dalam proyek ini, Kami menggunakan arsitektur EfficientNetB3 untuk melakukan klasifikasi penyakit tanaman mangga berdasarkan citra daun. EfficientNetB3 adalah salah satu model dalam keluarga EfficientNet yang terkenal karena kemampuannya dalam mengoptimalkan ukuran model serta efisiensi komputasi melalui teknik compound scaling. Teknik ini melibatkan penskalaan serempak pada tiga dimensi: lebar (width), kedalaman (depth), dan resolusi gambar (resolution).
Berikut adalah ilustrasi alur kerja dalam sistem klasifikasi penyakit daun mangga menggunakan EfficientNetB3:

Gambar 2. Alur kerja metode klasifikasi menggunakan EfficientNetB3.
Source: https://www.researchgate.net/figure/a-EfficientNet-B3-model-architecture-b-Proposed-layers_fig4_382650712
Persamaan Matematis yang kami gunakan sebagai berikut :
\[\hat{y} = f_{\theta}(\mathbf{x}) = \mathrm{Softmax}(W \cdot \text{GAP}(\mathcal{B}(\mathbf{x})) + b)\]yang dimana :
$\mathbf{x}$ merupakan Input citra (misal: $224 \times 224 \times 3$)
$\mathcal{B}(\mathbf{x})$ merupakan Output fitur dari backbone EfficientNetB3 (blok MBConv bertumpuk)
$\text{GAP}(\cdot)$ merupakan Global Average Pooling — merata-ratakan fitur spasial per channel
$W, b$ merupakan Bobot dan bias dari lapisan dense terakhir (klasifikasi)
$\mathrm{Softmax}(\cdot)$ merupakan Mengubah output menjadi distribusi probabilitas kelas
$\hat{y} \in \mathbb{R}^C$ merupakan Output model berupa probabilitas untuk tiap kelas penyakit daun ($C$)
$f_{\theta}(\cdot)$ merupakan Fungsi model EfficientNetB3 dengan parameter
Dalam proyek ini, Kami akan membangun sistem klasifikasi penyakit pada daun mangga menggunakan model EfficientNetB3. Proses utamanya meliputi:
- Pengumpulan dan preprocessing citra daun: Langkah pertama, citra daun diambil dan diolah agar sesuai dengan ukuran dan kualitas yang dibutuhkan oleh model.
- Pelatihan model EfficientNetB3: Kemudian, model dilatih menggunakan dataset citra daun yang sudah diberi label penyakit.
- Validasi dan pengujian: Kemudian, model diuji dengan data yang tidak digunakan pada pelatihan untuk mengukur akurasi dan performa klasifikasi.
Desain Eksperimentasi
A. Desain Eksperimentasi
Berikut adalah beberapa aspek yang kami lakukan dan gunakan dalam eksperimentasi:
| Aspek | Detail |
|---|---|
| Data & Split | 70 % data latih • 15 % data validasi • 15 % data uji |
| Preprocessing | Resize 224 × 224 • Normalisasi [0,1] • Augmentasi: rotasi (±40°), flip H/V, shift ±20 %, zoom ±30 %, brightness 40–60 % |
| Model | EfficientNetB3 pralatih (ImageNet) sebagai backbone; head: BatchNorm → Dense(128)+ReLU → Dropout(0.3) → Dense(C)+Softmax |
| Lingkungan | TensorFlow 2.x, Keras • GPU NVIDIA RTX 2050 • scikit-learn, pandas, matplotlib, seaborn |
| Optimizer | Adam |
| Learning rate | 1×10⁻³ (warm-up, 5 epoch) → 1×10⁻⁵ (fine-tune, 20 epoch) |
| Batch size | 40 |
| Epochs | 25 (5 warm-up + 20 fine-tune) |
| EarlyStopping | monitor='val_loss', patience=5 |
| ReduceLROnPlateau | monitor='val_loss', factor=0.2, patience=3, min_lr=1×10⁻⁷ |
| Metrik | Training/Validation Loss & Accuracy, Test Accuracy, F1-score per kelas, Confusion Matrix, Classification Report |
B. Dataset
Dataset yang digunakan berisi gambar daun mangga yang mewakili berbagai kondisi, baik daun sehat maupun daun yang terinfeksi penyakit. Setiap gambar telah diberi label sesuai dengan jenis penyakitnya, seperti Anthracnose, Bacterial Canker, Cutting Weevil, Die Back, Gall Midge, Powdery Mildew, Sooty Mould, dan kelas Healthy.
Dataset yang kami gunakan berasal dari Kaggle : https://www.kaggle.com/datasets/aryashah2k/mango-leaf-disease-dataset
Berikut adalah contoh gambar citra daun mangga dari beberapa kelas penyakit dalam dataset:

Gambar 3. Contoh citra daun mangga dari semua kelas penyakit.
- Jumlah total gambar: > 4.000 citra daun (detail jumlah setiap kelas dapat dilihat pada visualisasi data). Berikut adalah visualisasi jumlah total gambar pada dataset secara keseluruhan:
.png?updatedAt=1748396757960)
Gambar 4. Diagram distribusi jumlah total gambar citra daun mangga berdasarkan kelas penyakit.
- Format gambar: JPG, resolusi bervariasi tetapi diubah menjadi 224×224 piksel saat pemrosesan
-
Pembagian dataset:
- Training: 70%
- Validation: 15%
- Testing: 15%
- Augmentasi data:
Proses augmentasi dilakukan untuk memperkaya data pelatihan dan mengurangi kemungkinan overfitting.
Implementasi dan Analisis Hasil
A. Implementasi
Pada tahap implementasi, kami menggunakan Python dengan framework TensorFlow dan Keras. Model EfficientNetB3 dipilih sebagai backbone dengan bobot pre-trained dari ImageNet, untuk mempercepat konvergensi dan meningkatkan akurasi.
Berikut adalah implementasi lengkap pembuatan model:
# Import library standar yang dibutuhkan
# Modul os digunakan untuk interaksi dengan sistem file
import os
# itertools digunakan untuk operasi kombinatorial, meskipun belum digunakan di tahap ini
import itertools
# cv2 dari OpenCV untuk memproses gambar
import cv2
# NumPy dan Pandas untuk manipulasi data numerik dan tabular
import numpy as np
import pandas as pd
# Visualisasi data dengan seaborn dan matplotlib
import seaborn as sns
sns.set_style('darkgrid') # Mengatur gaya visualisasi seaborn
import matplotlib.pyplot as plt
# Visualisasi missing value dengan missingno
import missingno as msno
# Plotly digunakan untuk visualisasi interaktif
from plotly.subplots import make_subplots
import plotly.graph_objects as go
from plotly.offline import iplot
# Import tools dari scikit-learn untuk evaluasi model dan pemisahan data
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report
# Import modul dari TensorFlow untuk membangun dan melatih model deep learning
import tensorflow as tf
from tensorflow import keras
# Model sequential dan berbagai komponen layer serta tools lainnya dari Keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam, Adamax
from tensorflow.keras.metrics import categorical_crossentropy
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Activation, Dropout, BatchNormalization
from tensorflow.keras import regularizers
# Callbacks yang digunakan untuk mengatur proses pelatihan
from keras.callbacks import EarlyStopping, LearningRateScheduler, ReduceLROnPlateau
# Preprocessing khusus untuk EfficientNetB3
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.efficientnet import preprocess_input
from tensorflow.keras.applications import EfficientNetB3
# Supaya warning yang tidak penting tidak ditampilkan di output
import warnings
warnings.filterwarnings("ignore")
# Menampilkan versi TensorFlow yang digunakan dan memastikan semua modul berhasil dimuat
print('we are currently using tensorflow version', tf._version_)
print ('modules loaded')
# Menentukan direktori tempat dataset gambar disimpan
data_dir = 'D:/path_dataset'
# Memberikan nama deskriptif untuk dataset, berguna untuk dokumentasi atau tampilan
ds_name = 'Penyakit Daun Mangga'
# Fungsi untuk mengambil path gambar dan label dari folder dataset
def generate_data_paths(data_dir):
filepaths = [] # Menyimpan path lengkap dari setiap gambar
labels = [] # Menyimpan nama label dari folder gambar (nama penyakit)
# Mendapatkan daftar folder (kelas) di dalam direktori dataset
folds = os.listdir(data_dir)
for fold in folds:
foldpath = os.path.join(data_dir, fold) # Path ke folder tertentu (misal: 'Antraknosa')
filelist = os.listdir(foldpath) # Daftar file gambar dalam folder tersebut
for file in filelist:
fpath = os.path.join(foldpath, file) # Path lengkap ke file gambar
filepaths.append(fpath)
labels.append(fold) # Nama folder dijadikan label gambar
return filepaths, labels # Mengembalikan list path dan label gambar
# Memanggil fungsi untuk mendapatkan semua path dan label gambar
filepaths, labels = generate_data_paths(data_dir)
# Fungsi untuk membentuk dataframe dari path dan label
def create_df(filepaths, labels):
# Mengubah list menjadi Series agar bisa dikombinasikan menjadi DataFrame
Fseries = pd.Series(filepaths, name='filepaths')
Lseries = pd.Series(labels, name='labels')
# Menggabungkan keduanya menjadi satu DataFrame
df = pd.concat([Fseries, Lseries], axis=1)
return df
# Membuat DataFrame yang berisi path gambar dan labelnya
df = create_df(filepaths, labels)
# Menampilkan 10 data pertama dari DataFrame
df.head(10)
# Fungsi untuk menampilkan jumlah gambar dalam dataset
def num_of_examples(df, name='df'):
print(f"jumlah gambar {name} memiliki sebanyak {df.shape[0]} gambar.")
# Memanggil fungsi untuk mencetak jumlah gambar pada dataset yang telah dibuat
num_of_examples(df, ds_name)
# Fungsi untuk menampilkan jumlah kelas unik (jenis penyakit) dalam dataset
def num_of_classes(df, name='df'):
print(f"jumlah jenis {name} memiliki {len(df['labels'].unique())} jenis penyakit")
# Memanggil fungsi untuk mencetak jumlah kelas penyakit dalam dataset
num_of_classes(df, ds_name)
# Fungsi untuk menampilkan jumlah gambar per jenis penyakit (kelas)
def classes_count(df, name='df'):
print(f"jenis {name} pada dataset sebagai berikut: ")
print("="*70)
print()
# Iterasi untuk setiap label unik dalam kolom 'labels'
for name in df['labels'].unique():
num_class = len(df['labels'][df['labels'] == name]) # Hitung jumlah gambar untuk label tersebut
print(f"jenis '{name}' memiliki {num_class} gambar")
print('-'*70)
# Memanggil fungsi untuk menampilkan distribusi jumlah gambar per kelas
classes_count(df, ds_name)
# Fungsi untuk menampilkan visualisasi distribusi kelas dalam dataset
def cat_summary_with_graph(dataframe, col_name):
fig = make_subplots(rows=1, cols=2,
subplot_titles=('Countplot', 'Persentase'),
specs=[[{"type": "bar"}, {'type': 'pie'}]])
# Grafik batang (bar chart) untuk jumlah gambar per label
fig.add_trace(go.Bar(y=dataframe[col_name].value_counts().values.tolist(),
x=[str(i) for i in dataframe[col_name].value_counts().index],
text=dataframe[col_name].value_counts().values.tolist(),
textfont=dict(size=20),
name=col_name,
textposition='auto',
showlegend=False,
marker=dict(color=colors)),
row=1, col=1)
# Grafik lingkaran (pie chart) untuk persentase gambar per label
fig.add_trace(go.Pie(labels=dataframe[col_name].value_counts().keys(),
values=dataframe[col_name].value_counts().values,
textfont=dict(size=20),
textposition='auto',
showlegend=False,
name=col_name,
marker=dict(colors=colors)),
row=1, col=2)
# Mengatur tampilan layout grafik
fig.update_layout(title={'text': col_name,
'y': 0.9,
'x': 0.5,
'xanchor': 'center',
'yanchor': 'top'},
template='plotly_white')
# Menampilkan grafik
fig.show()
# Daftar warna untuk visualisasi
colors = ['#494BD3', '#E28AE2', '#F1F481', '#79DB80', '#DF5F5F',
'#69DADE', '#C2E37D', '#E26580', '#D39F49', '#B96FE3']
# Memanggil fungsi untuk menampilkan distribusi label pada dataset
cat_summary_with_graph(df, 'labels')
# Fungsi untuk memeriksa apakah terdapat nilai kosong (null) dalam DataFrame
def check_null_values(df, name='df'):
# Menghitung total nilai null di seluruh kolom
num_null_vals = sum(df.isnull().sum().values)
if not num_null_vals:
print(f"dataset {name} tidak memiliki nilai null")
else:
print(f"Dataset {name} memiliki {num_null_vals} nilai null")
print('-'*70)
print('Total null values in each column:\n')
print(df.isnull().sum())
# Memanggil fungsi untuk memeriksa nilai null pada dataset
check_null_values(df, ds_name)
# Visualisasi distribusi missing values (jika ada) menggunakan library Missingno
msno.matrix(df)
# Menambahkan judul ke plot
plt.title('Distribusi Nilai yang Hilang/Missing Values', fontsize=30, fontstyle='oblique');
# Menampilkan 10 baris pertama dari dataset untuk melihat contoh data
df.head(10)
# Membagi dataset menjadi data latih (train), validasi (validation), dan uji (test)
train_df, dummy_df = train_test_split(df, train_size=0.7, shuffle=True, random_state=123)
valid_df, test_df = train_test_split(dummy_df, train_size=0.5, shuffle=True, random_state=123)
# Fungsi untuk menampilkan jumlah gambar dalam sebuah dataframe
def num_imgs(df, name='df'):
print(f"Jumlah data {name} ada sebanyak {len(df)} gambar")
# Menampilkan jumlah gambar pada setiap subset data
num_imgs(train_df, 'Training '+ds_name)
num_imgs(valid_df, 'Validation '+ds_name)
num_imgs(test_df, 'Testing '+ds_name)
# Menampilkan jumlah kelas unik pada setiap subset data
num_of_classes(train_df, "Training "+ds_name)
num_of_classes(valid_df, "Validation "+ds_name)
num_of_classes(test_df, "Testing "+ds_name)
# Menampilkan jumlah gambar per kelas pada setiap subset data
classes_count(train_df, 'Training '+ds_name)
classes_count(valid_df, 'Validation '+ds_name)
classes_count(test_df, 'Testing '+ds_name)
# Definisikan parameter dasar untuk pemrosesan gambar dan batch size
batch_size = 40 # Jumlah gambar yang diproses sekaligus dalam satu batch
img_size = (224, 224) # Ukuran gambar input yang akan di-resize (sesuai input EfficientNetB3)
channels = 3 # Jumlah channel warna (RGB)
img_shape = (img_size[0], img_size[1], channels)
# Menghitung jumlah batch dan batch size untuk data testing agar efisien
ts_length = len(test_df) # Total data pada testing set
test_batch_size = max(
sorted([
ts_length // n
for n in range(1, ts_length + 1)
if ts_length % n == 0 and ts_length / n <= 80
])
)
test_steps = ts_length // test_batch_size # Jumlah batch steps untuk testing
# Fungsi scalar sebagai preprocessing sederhana (bisa diganti dengan preprocess_input dari EfficientNet jika perlu)
def scalar(img):
return img
# Membuat ImageDataGenerator untuk augmentasi data training agar model lebih robust
tr_gen = ImageDataGenerator(
preprocessing_function=scalar,
rotation_range=40, # Rotasi acak gambar sampai 40 derajat
width_shift_range=0.2, # Pergeseran horizontal gambar hingga 20%
height_shift_range=0.2, # Pergeseran vertikal gambar hingga 20%
brightness_range=[0.4, 0.6], # Rentang kecerahan gambar yang diacak
zoom_range=0.3, # Zoom acak hingga 30%
horizontal_flip=True, # Flip horizontal acak
vertical_flip=True # Flip vertikal acak
)
# Membuat ImageDataGenerator untuk validasi dan testing (bisa juga tanpa augmentasi, tapi di sini sama saja)
ts_gen = ImageDataGenerator(
preprocessing_function=scalar,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
brightness_range=[0.4, 0.6],
zoom_range=0.3,
horizontal_flip=True,
vertical_flip=True
)
# Membuat generator data untuk training dari dataframe, mengatur label dan ukuran gambar
train_gen = tr_gen.flow_from_dataframe(
train_df,
x_col='filepaths',
y_col='labels',
target_size=img_size,
class_mode='categorical', # Karena klasifikasi multi-kelas
color_mode='rgb',
shuffle=True,
batch_size=batch_size
)
# Generator data untuk validasi
valid_gen = ts_gen.flow_from_dataframe(
valid_df,
x_col='filepaths',
y_col='labels',
target_size=img_size,
class_mode='categorical',
color_mode='rgb',
shuffle=True,
batch_size=batch_size
)
# Generator data untuk testing, tanpa shuffle agar hasil evaluasi konsisten
test_gen = ts_gen.flow_from_dataframe(
test_df,
x_col='filepaths',
y_col='labels',
target_size=img_size,
class_mode='categorical',
color_mode='rgb',
shuffle=False,
batch_size=test_batch_size
)
# Mengambil dictionary nama kelas dan indeksnya dari generator
g_dict = train_gen.class_indices # Contoh: {'sehat': 0, 'antraknosa': 1, 'embun': 2}
classes = list(g_dict.keys()) # List nama kelas: ['sehat', 'antraknosa', 'embun']
# Mengambil satu batch gambar dan label dari train_gen
images, labels = next(train_gen) # Satu batch gambar dan label (jumlah = batch_size)
# Membuat canvas plot untuk 16 gambar (4x4)
plt.figure(figsize=(20, 20))
for i in range(16): # Menampilkan 16 gambar pertama dari batch
plt.subplot(4, 4, i + 1) # Buat subplot 4 baris × 4 kolom
image = images[i] / 255 # Normalisasi (karena data masih 0–255, dibagi agar jadi 0–1)
plt.imshow(image) # Tampilkan gambar
index = np.argmax(labels[i]) # Konversi one-hot label ke indeks kelas
class_name = classes[index] # Ambil nama kelas dari indeks
plt.title(class_name, color='blue', fontsize=15) # Judul gambar: nama kelas
plt.axis('off') # Matikan sumbu untuk tampilan lebih bersih
plt.show()
# Struktur Model
Pembuatan Model Umum(*Generic*)
# Membuat Struktur Model
img_size = (224, 224)
channels = 3
img_shape = (img_size[0], img_size[1], channels)
class_count = len(list(train_gen.class_indices.keys())) # untuk menentukan jumlah kelas dalam lapisan padat
# membuat model yang telah dilatih sebelumnya,kita akan menggunakan EfficientNetB3 dari keluarga EfficientNet.
base_model_b3 = EfficientNetB3(
include_top=False,
weights="imagenet",
input_shape=img_shape,
pooling='max'
)
base_model_b3.trainable = False
model_b3 = Sequential([
base_model_b3,
BatchNormalization(),
Dense(128, activation='relu'),
Dropout(0.3),
Dense(class_count, activation='softmax')
])
model_b3.compile(optimizer=Adam(learning_rate=1e-3),
loss='categorical_crossentropy',
metrics=['accuracy'])
model_b3.summary()
Dengan langkah-langkah ini, model EfficientNetB3 berhasil diimplementasikan untuk klasifikasi penyakit pada tanaman mangga menggunakan citra daun. Model ini menunjukkan performa yang baik pada data pelatihan, validasi, dan pengujian.
B. Analisis Hasil
Berdasarkan hasil pelatihan model, diperoleh metrik evaluasi sebagai berikut:
- Train Loss: 0.0197
- Train Accuracy: 99.37%
- Validation Loss: 0.0301
- Validation Accuracy: 98.75%
- Test Loss: 0.0245
- Test Accuracy: 99.33%
Hasil ini menunjukkan bahwa model memiliki performa yang sangat baik, baik pada data pelatihan, validasi, maupun pengujian. Perbedaan nilai akurasi dan loss antar dataset ini juga relatif kecil, menunjukkan bahwa model tidak mengalami overfitting atau underfitting yang signifikan.
Visualisasi grafik Training Loss dan Validation Loss selama proses pelatihan ditampilkan pada gambar berikut:
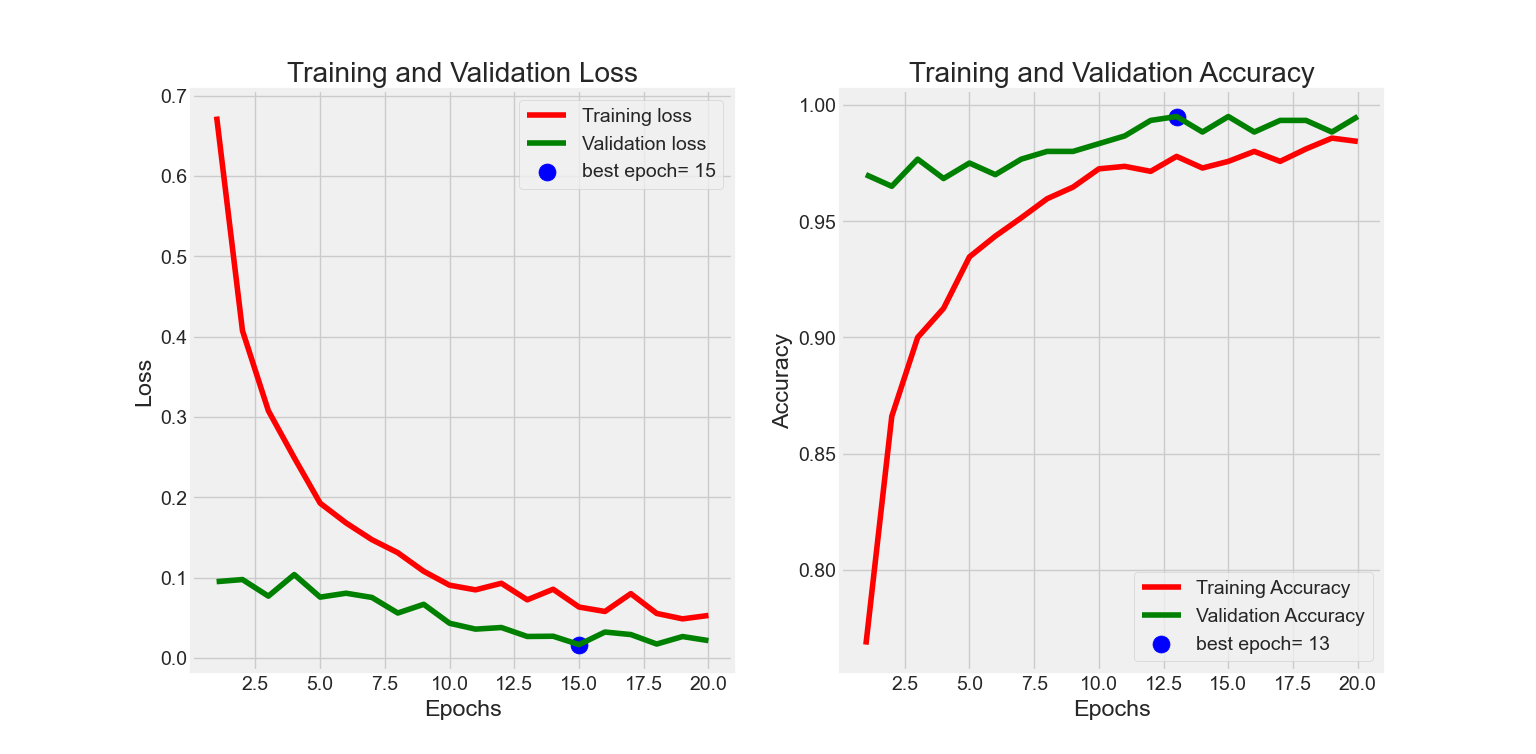
Gambar 5. Grafik yang menunjukkan tren penurunan loss selama proses pelatihan dan validasi model.
Referensi:
- FAO. (2023). Impact of Plant Diseases on Mango Production. Food and Agriculture Organization.
- Smith, J., et al. (2022). Deep Learning for Plant Disease Detection: A Review. Journal of Agricultural Informatics, 13(1), 45-60.
- Lee, H., et al. (2021). Comparative Study of CNN Architectures for Leaf Disease Classification. Computers and Electronics in Agriculture, 180, 105876.